SIRIUSでサイトやページを検索エンジンに表示させない方法

ウェブサイトを運営していると、サイトや特定のページを検索エンジンに登録・表示させたくない場面があるかと思います。
ここではrobots.txtやnoindexを使用した、クローラーを回避して検索エンジンに登録・表示させない方法を解説します。
サイトを完全に非公開にしたい場合はこちら
検索エンジンに表示されないようにするには?
GoogleやYahoo! などの検索エンジンでは、「クローラー」と呼ばれるロボットがネット上にあるサイトを巡回し、検索エンジンのデータベースを更新していきます。
そのため、公開(アップロード)したサイトやページがデータベースにインデックスされ、検索結果に表示されるようになります。
しかし、作成したサイトやページを検索エンジンにインデックスさせたくない場合があります。
例えば下記のような場合です。
- テストで公開しているページ
- 会員向けコンテンツのページ
- コンテンツの内容が薄いページ
このような検索結果に表示させたくないページがある場合、robots.txtやnoindexで検索エンジンへのインデックスを制御することが可能です。
具体的にはrobots.txtやnoindexを設定することで、クローラーのクロールを拒否することで検索エンジンへの登録・表示を回避します。
robots.txtでサイト全体でクロール拒否
メタタグであるnoindexはページごとに設定する必要があります。SIRIUSではテンプレートの編集が必要になるためサイト全体に対して行うのは色々と面倒です。
そこでサイト全体でクロール拒否できるrobots.txtを使用します。
robots.txtを作成する
robots.txtはただのテキストファイルなので、新規テキストファイルを作成しファイル名を「robots.txt」に変更します。「.txt」の部分は拡張子です。
あとは一般的なテキストエディタ(Windowsならメモ帳)で内容を記述するだけです。以下のテキストをテキストファイルに貼り付けてください。
サイト全体のクロール拒否する場合
User-agent: * Disallow: /
特定のディレクトリ(カテゴリー)のクロール拒否する場合
User-agent: * Disallow: /カテゴリー名/
記述の意味
- User-agent: * →全てのクローラを対象とする
- Disallow: / → robots.txt を設置した階層以下をクロール拒否
全ての検索エンジンに対しサイト全体のクロール拒否する場合のrobots.txtを作成したのでダウンロードしてご使用ください。
robots.txtを設置する
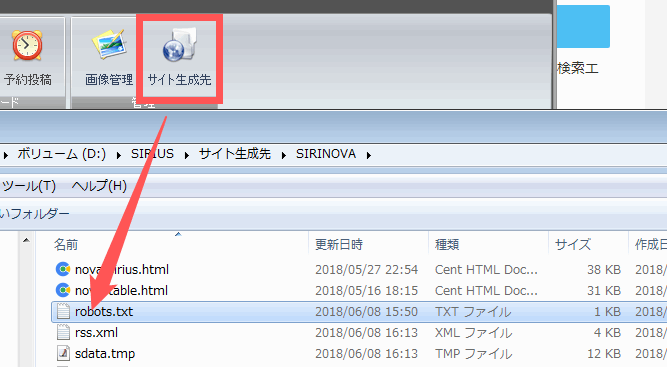
robots.txtはサイトのルートディレクトリ(第一階層フォルダ)にアップロードする必要があります。
SIRIUSの場合は「サイト生成先」からサイトのフォルダを開いてrobots.txtを設置します。
robots.txtの動作を確認する
robots.txtが正常に動作しているかはGoogleサーチコンソールのrobots.txt テスターで確認できます。またクロールの動作を確認しながらrobots.txtの編集も可能です。
Googleサーチコンソールの左側メニューの「クロール」→「robots.txt テスター」をクリックしてアップロード済みのrobots.txtをチェックします。
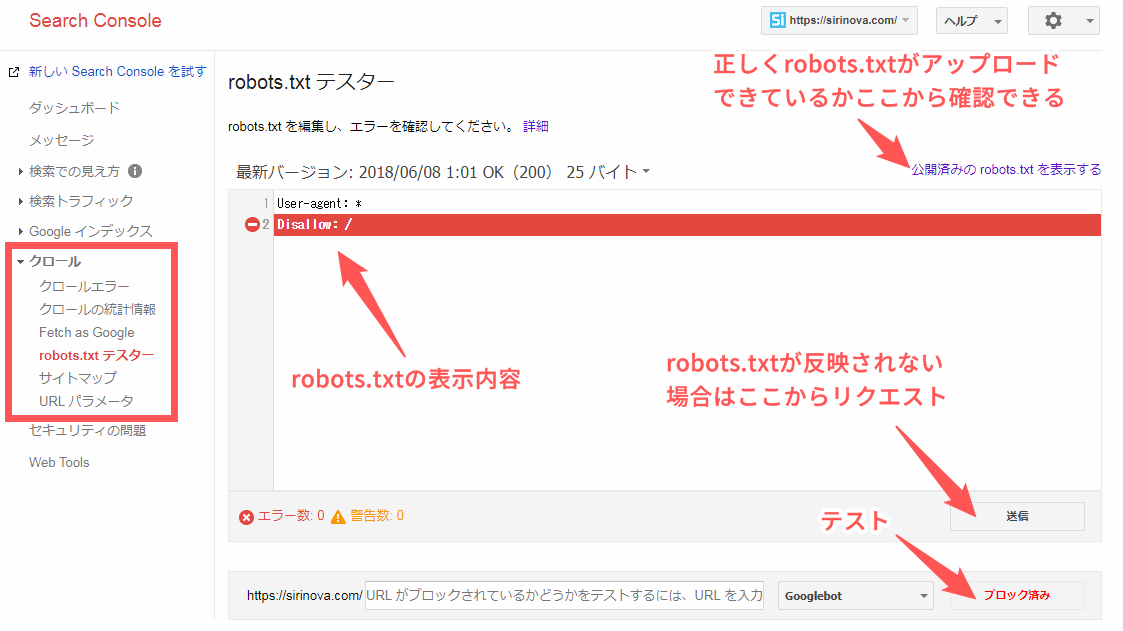
「テスト」をクリックして「ブロック済み」と表示されれば成功です。
クロール拒否を解除する場合はサイト生成先フォルダとアップロード先(サーバー)からrobots.txtを削除して、「送信」ボタンからリクエストをしてrobots.txtの変更を反映させてください。
特定のページをnoindexでクロール拒否
noindexはメタタグなので設定するにはテンプレートの<head>内に以下の記述が必要です。
<meta name=”robots” content=”noindex”>
しかしSIRIUSにはページ単位でnoindexが設定できる機能があるので、それを使用します。
ページにnoindexを設定する
ページにnoindexを設定するには「ページ設定」から「上級者向け設定」タブを開いて「定型文→検索エンジン拒否」を選択します。
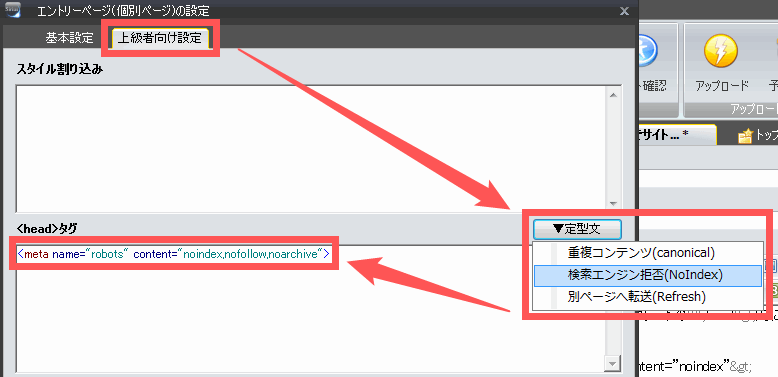
すると以下が記入されます。
<meta name="robots" content="noindex,nofollow,noarchive">
noindexはインデックスの拒否、nofollowはページにあるリンクを辿らせない、noarchiveはキャッシュの拒否です。特に改変せずこのままで大丈夫です。
これで設定したページからクロールを拒否することが可能になりました。robots.txtとは違い一括管理ができないので、どのページにnoindexを設定したのか忘れないよう注意が必要です。
注意点
クロール拒否の解除忘れ
robots.txtとnoindexは一度設定すると自分で解除するまで検索結果に表示されなくなるため、間違って設定すると悲惨なことになります。
いずれ設定を解除する公開前のテストサイトなどで使用する場合は、メモを取るなどして解除のし忘れに注意しましょう。
noindexとrobots.txtの同時使用
すでにインデックスされているページにnoindexを設定しrobots.txtでクロールもブロックしてしまうと、クローラーは該当ページのクロールが行えずnoindexを認識することができなくなります。
そうなると非表示にしたいページがいつまでも検索結果に表示されたままになってしまうので注意してください。
完全に拒否したい場合はnoindexを使用
robots.txtでクロールの拒否を行っても例外的にブロックしたURLがインデックスされてしまう可能性があることに注意しましょう。例えば他サイトから被リンクを受けている場合などです。
完全に検索結果に表示させたくない場合は、robots.txtではなくnoindexを使用する必要があります。
ページ設定の「公開設定」について
ページ設定の「公開設定」はサイト生成時にページのファイルを作成するかどうかの設定です。
robots.txtとnoindexが検索結果での非表示に対し、「公開設定」はサーバーからページを削除し「非公開」を設定することでページを完全に非公開(削除)することができます。
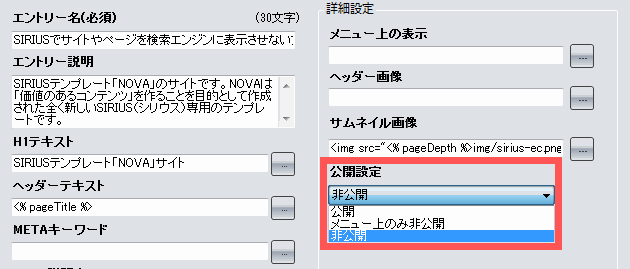
公開
公開されます。
メニュー上のみ非公開
サイドメニューやカテゴリーページの記事一覧、エントリーページの関連記事などで非表示になります。ページ自体は作成されるので閲覧することができ、サイトマップにも表示されます。
会員ページやお問い合わせページなど、特定のリンクからしか辿れないようにしたいページに使用します。
非公開
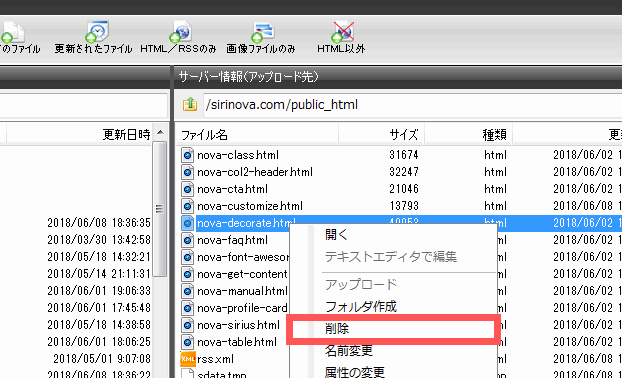
ページが作成されないので書きかけの記事などに設定します。一度公開したページを「非公開」に設定するとサイト生成時に作成されず、古いページがサーバー上に残ったままになります。
アップロード先(サーバー)からページを削除するには、「アップロード」ボタンをクリックしてページファイルを右クリックし「削除」をクリックします。